

type
Post
status
Published
date
Aug 16, 2023
slug
chatgpt-code-pdf
summary
tags
ChatGPT
AI
category
人工智能
icon
password
Property
Aug 25, 2023 05:15 PM
URL

Notion Ai 总结:
该文章介绍了如何使用 GPT-4 代码解释器将 PDF 页面分割成两个页面。使用 PyMuPDF 和 Pillow 包,将每一页转换为 4 倍高分辨率的图像,然后在图像上进行分割,最后使用 PIL 库将分割后的 4 倍高分辨率图像重新组合成 PDF。作者还尝试使用 Wolfram 语言解决该问题,但效率较低。
1. 问题
昨天遇到一个问题,我下载的 PDF 是一页里面包含两页的,像这样:

可以看到一页里面实际上是两页,所以我想将中间切开,然后组成一个新的 PDF。
2. GPT-4 代码解释器 解决
于是我请教了 ChatGPT ,马上就解决了,下面是交谈的记录

最后核心的代码是这样的:
- 首先安装包
- 运行代码
我是在 Google 的 Colab 中运行的大概是两分钟搞定了,最后结果很完美,极快地解决了问题
3. 使用 wolfram 语言解决
因为是 GPT-4 做出来的,所以我就想能否用我擅长的 wolfram 语言解决呢?同样地我也是咨询了 GPT-4 给出了基础的代码,是这样的:
3.1 初始版本
第一步:导入 PDF 文件
我们先导入整个 PDF 文件。
第二步:定义分割函数
我们定义一个函数来分割页面,将其切成两半。
第三步:应用分割函数到每一页
我们将
splitPage 函数应用到 PDF 文件的每一页。这里
splitPages 是一个包含列表的列表,其中每个子列表包含两个分割的页面。第四步:组合并导出到新的 PDF 文件
我们需要将这些页面整理成一个列表,然后导出为新的 PDF 文件。
现在,新的 PDF 文件
newfile.pdf 应该包含原始 PDF 文件的每一页分割后的两个页面,按顺序排列。每个原始页面分割为两个新的页面,所以新的 PDF 文件的总页数应该是原始 PDF 文件的两倍。使用上面的步骤有个问题,就是所有的页面都会在一个页面里面。
3.2 改进版本
我在 mse(这个帖子) 上找了下答案,然后才可以的的。改进后的代码是这样的:
开始测试的时候我是用的小文件,也就是说只有几页的那个PDF。这个是可以的但是当我给了整个PDF也就是几百页的那个PDF之后。我发现它这个根本就处理不了你可以看下它的那个内存的占比。
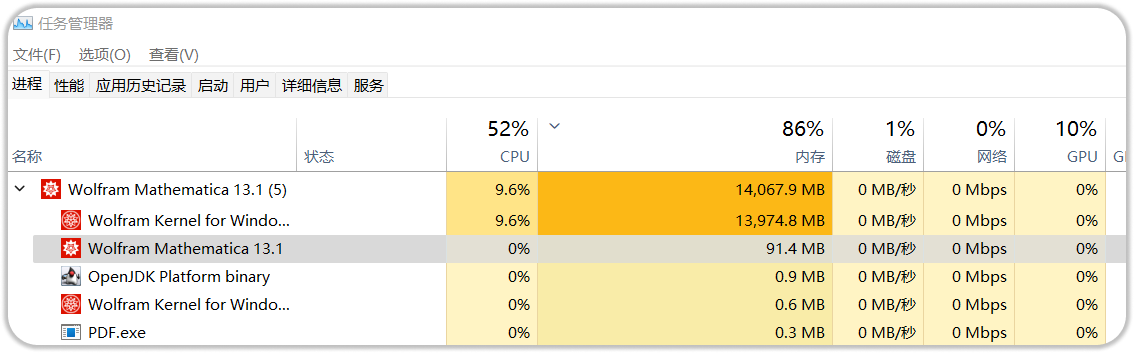
运行了十几分钟,然后内存占用了14个G。结果还是没有出来那可以看到。这个 wolfram 语言的效率还是有那么一点点低的。所以我就感觉 GPT4 还是很牛的。
- 作者:我心永恒
- 链接:https://wxyhgk.com/article/chatgpt-code-pdf
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。


